总览
随着模型越来越大,单卡的算力和显存已经无法满足需求,多卡并行顺势而生。通信在多卡并行中扮演着重要角色,对性能也有影响。本文总结一些常见的通信元语,更多关注于推理(而不是训练)。
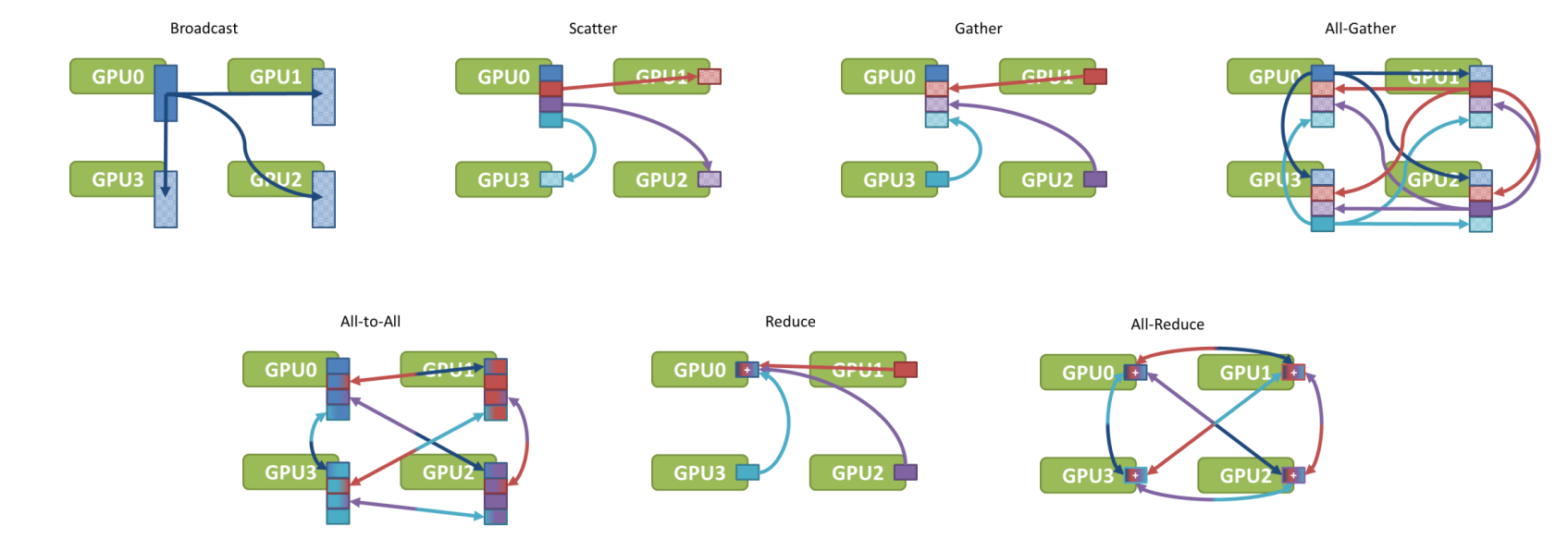
通信元语
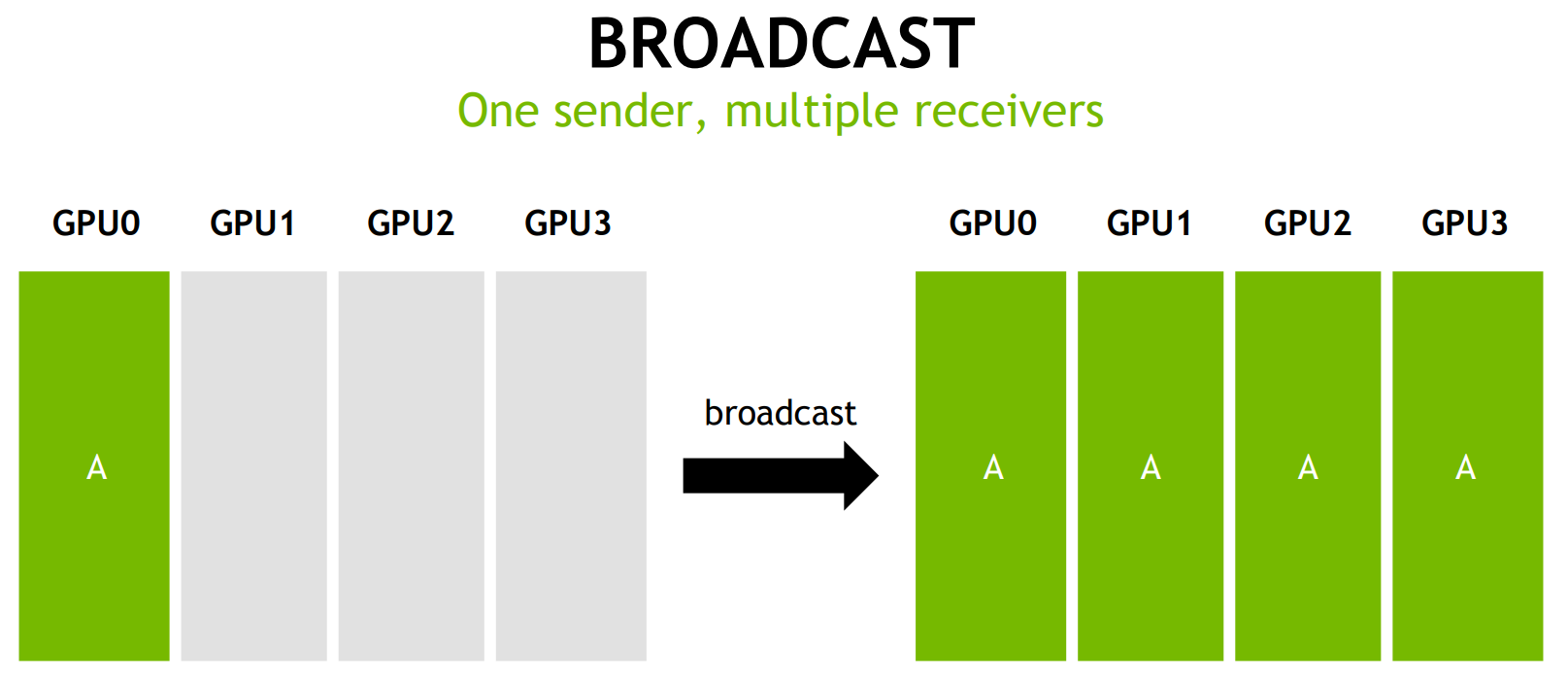
Broadcast
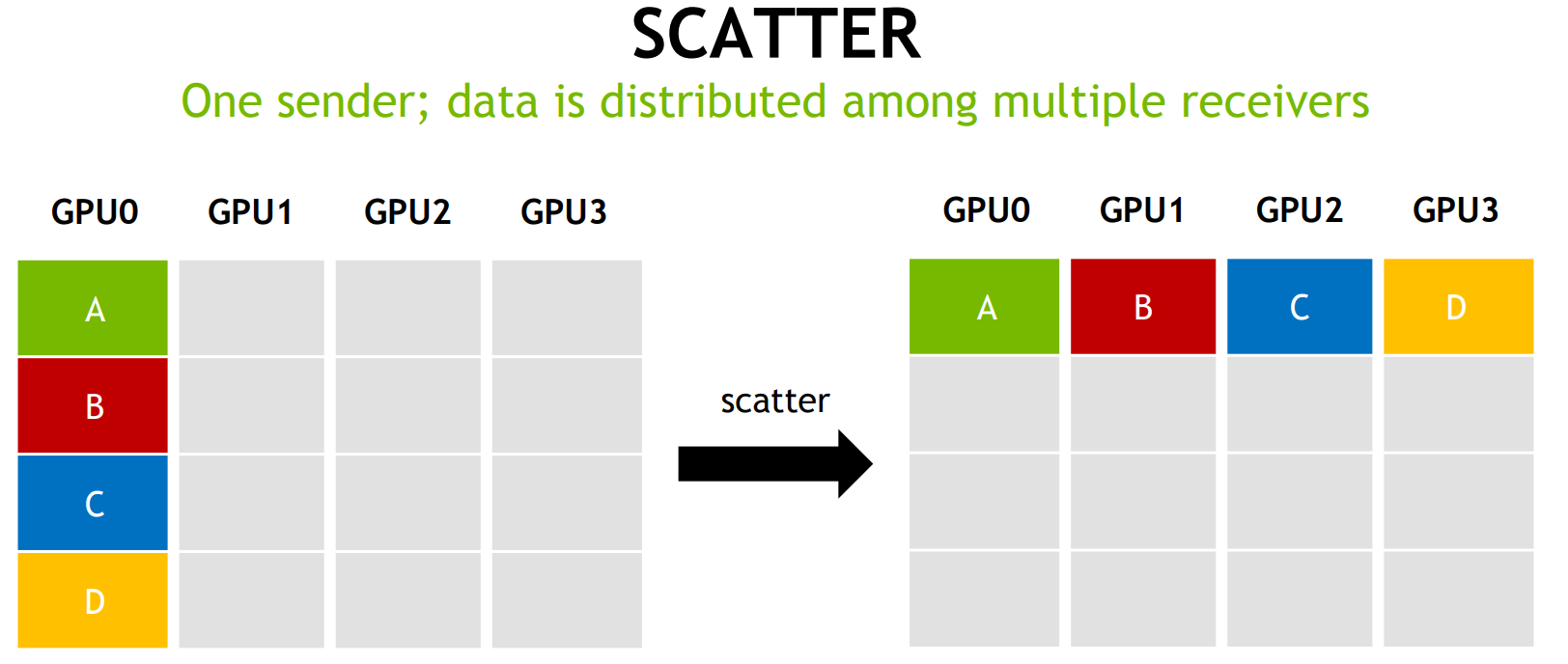
Scatter
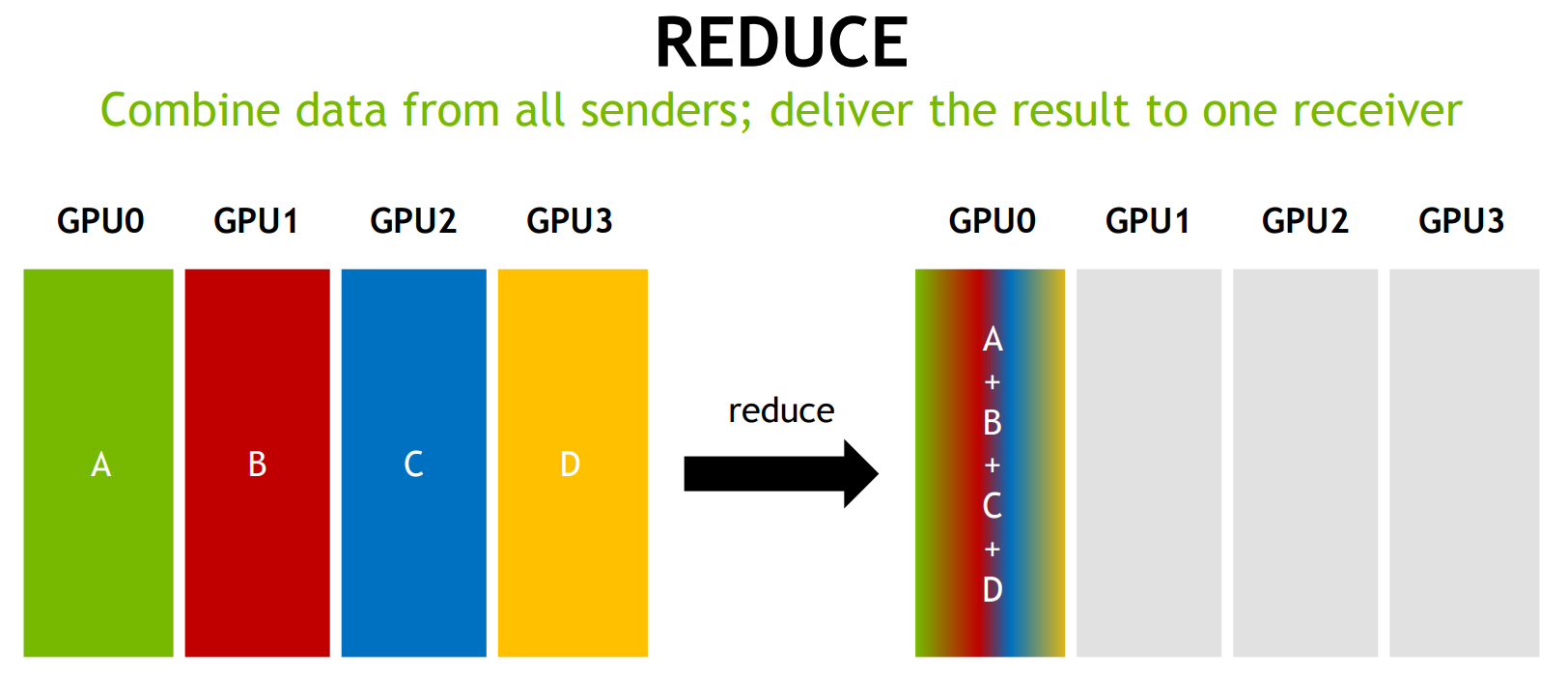
Reduce
AllReduce
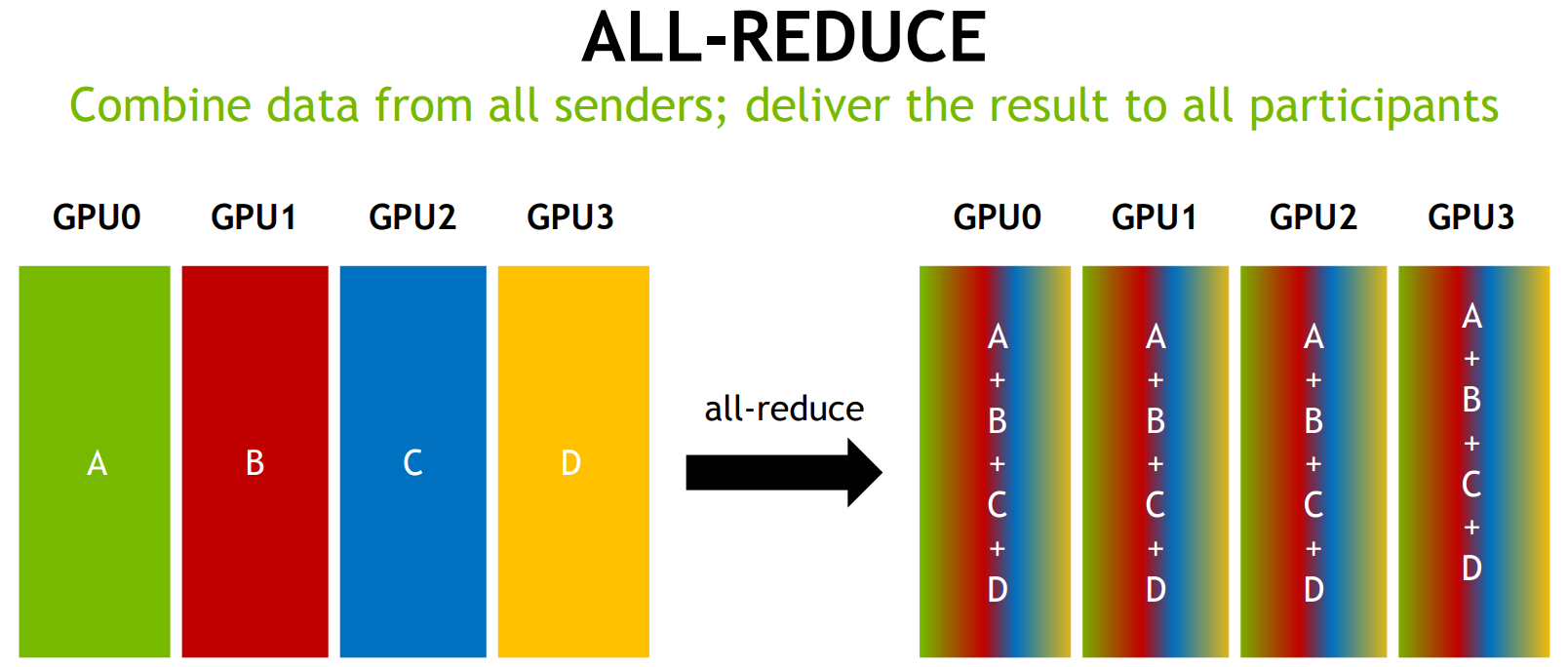 通信量:
通信量:
数学性质(参考):AllReduce = reduceScatter + allGather
典型使用场景:TP后的加和规约。
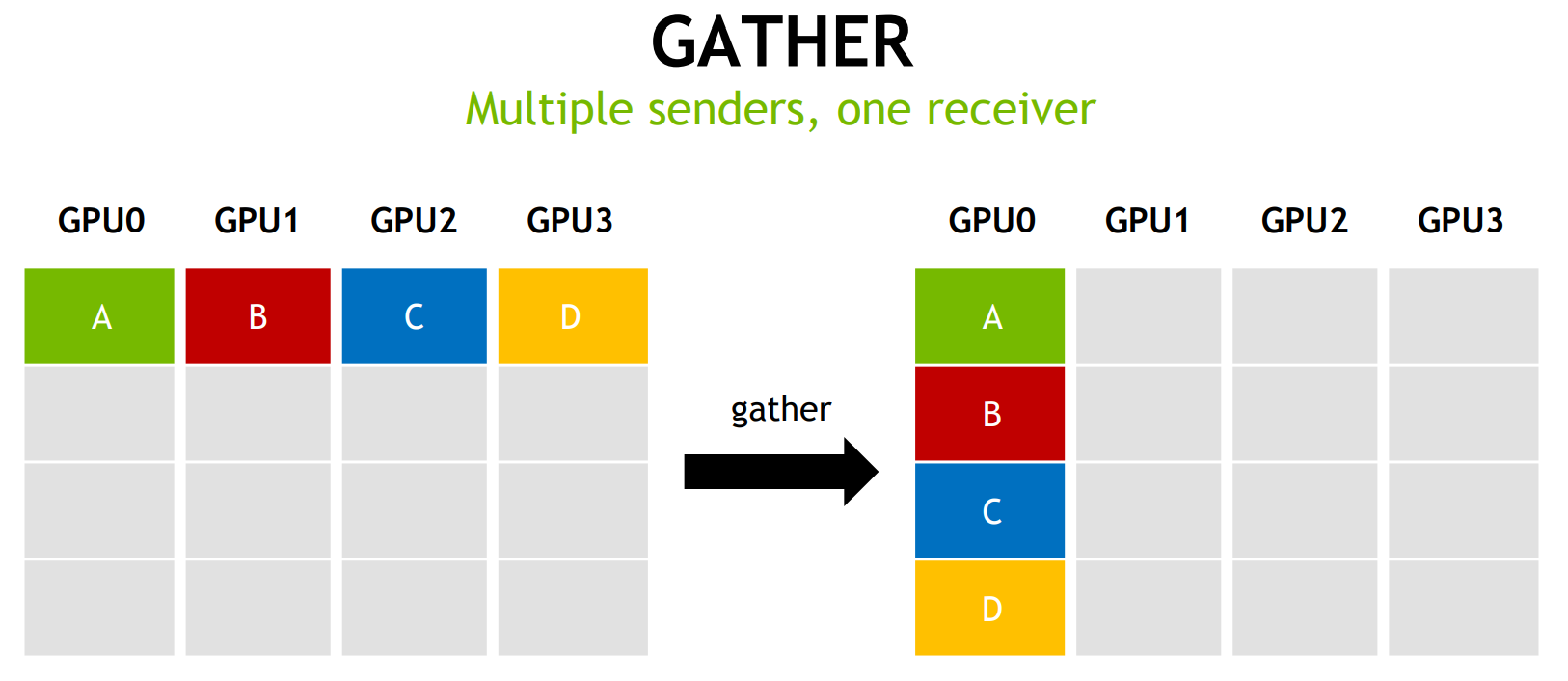
Gather
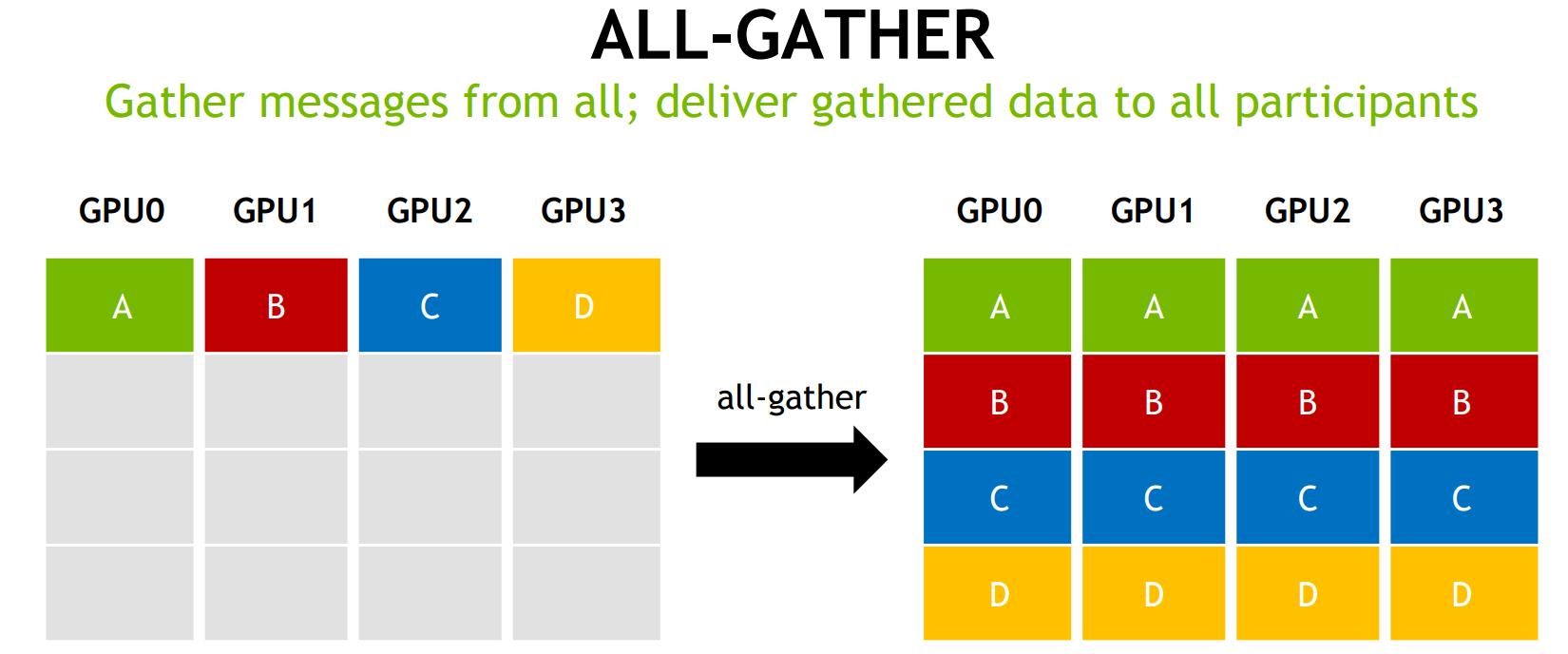
AllGather
ReduceScatter

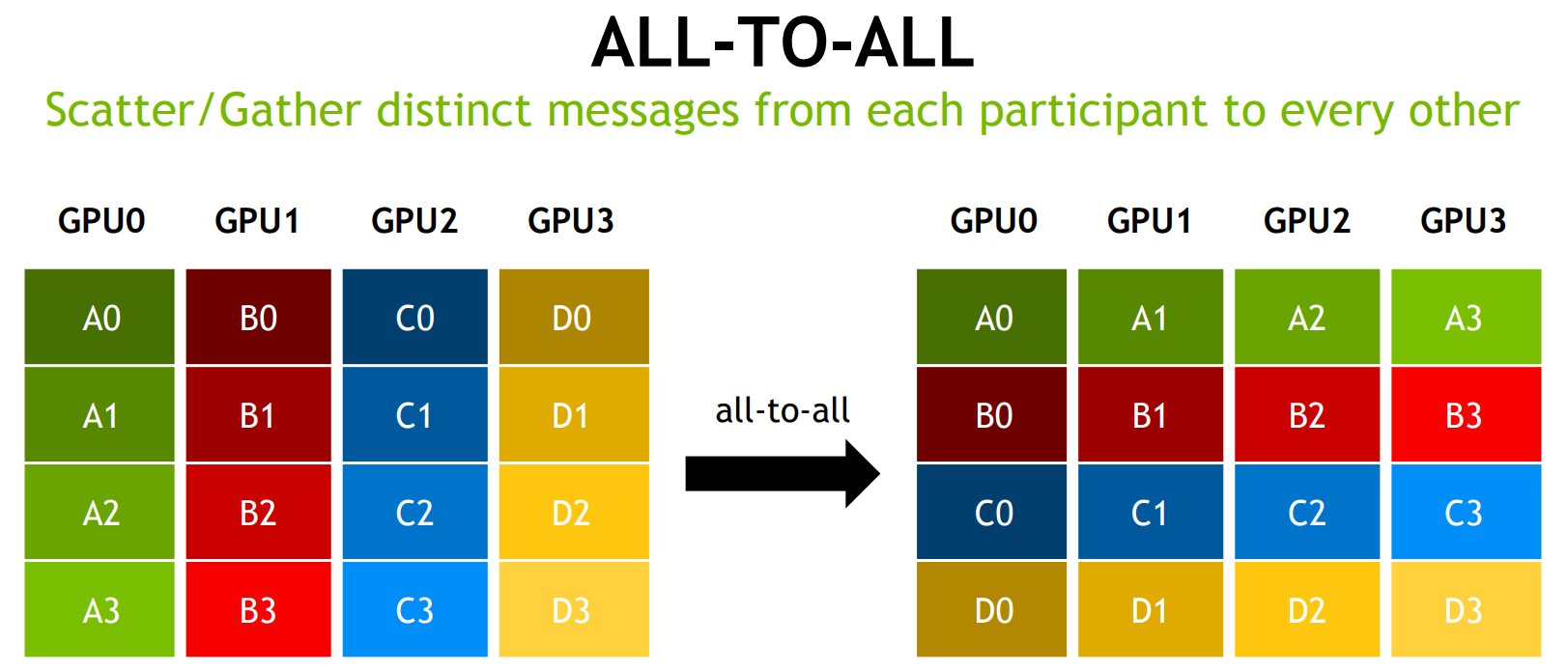
AlltoAll
https://images.nvidia.com/events/sc15/pdfs/NCCL-Woolley.pdf
https://www.zhihu.com/search?type=content&q=moe%20alltoall
https://blog.csdn.net/daydayup858/article/details/149742695
从零实现一个MOE(专家混合模型) - KaiH的文章 - 知乎 https://zhuanlan.zhihu.com/p/701777558
DeepSeek模型MOE结构代码详解 - AI布道Mr.Jin的文章 - 知乎 https://zhuanlan.zhihu.com/p/1896490149577200132
MoE 训练到底是开 TP 还是 EP? - xffxff的文章 - 知乎 https://zhuanlan.zhihu.com/p/13997146226
彻底搞懂MoE的EP并行(基于vLLM) - 九山海的文章 - 知乎 https://zhuanlan.zhihu.com/p/1911059432953061899
https://zhuanlan.zhihu.com/p/681692152
https://www.zhihu.com/search?type=content&q=moe%20%E5%B9%B6%E8%A1%8C
https://www.zhihu.com/search?type=content&q=moe%20%E5%B9%B6%E8%A1%8C
https://mp.weixin.qq.com/s/9oPHFf519DLX1ictcnirXQ
https://apxml.com/courses/mixture-of-experts/chapter-4-scaling-moe-distributed-training/all-to-all-communication-moe
这一段终于给我看懂了。至于EP和DP为什么习惯组合在一起用先不谈,当这二者在一起用时,是怎么个逻辑,为什么这个时候会用到AlltoAll,倒是终于抓到了点眉目。
首先理解这个alltoall,先不要困在计算形式上,而是想它的计算本质:每个device都想将它的subset发到每一个其他device上(包括它自己),每个device都接收来自其他device的subset. 这里一个All是dp rank,一个all是ep rank (在这个语境下,强调i, j对应关系的,都是虚张声势了。)
考虑dp_size = ep_size:
alltoall dispatch: all (dp) to all (ep). dp rank N上的subset (token),会分散到不同的ep rank device上。另一方面,每一个ep rank device, 将收到来自不同dp rank的subset。
alltoall combine: all (ep) to all (dp). ep rank N上的subset (计算结果),会汇总回token对应的dp rank上。另一方面,每一个dp rank,将收到来自不同ep rank的subset.
完美。
至于两个阶段里的分group,大概是实现方式了。分好group就可以复用已有的alltoall算子实现。